Дезоксирибонуклеїнова кислота
Дезоксирибонуклеї́нова кислота́ (ДНК) — один із двох типів природних нуклеїнових кислот, яка забезпечує зберігання, передавання від покоління до покоління і впровадження генетичної програми розвитку й діяльності живих організмів. Основне призначення ДНК в клітинах — довготривале зберігання відомостей про структуру РНК і білків.

У клітинах еукаріотів (наприклад, тварин, рослин або грибів) ДНК міститься в ядрі клітини в складі хромосом, а також в деяких клітинних органелах (мітохондріях і пластидах). У клітинах прокаріотів (бактерій і архей) кільцева або лінійна молекула ДНК, так званий нуклеоїд, міститься в цитоплазмі й прикріплена зсередини до клітинної мембрани. У них і у нижчих еукаріотів (наприклад дріжджів) трапляються також невеликі автономні кільцеві молекули ДНК, так звані плазміди. Крім того, одно- або дволанцюгові молекули ДНК можуть утворювати геном ДНК-вірусів.
З хімічної точки зору ДНК — це довга полімерна молекула, що складається з послідовності блоків — нуклеотидів. Кожний нуклеотид складається з азотистої основи, цукру (дезоксирибози) і фосфатної групи. Зв'язки між нуклеотидами в ланцюгу, утворюються дезоксирибозою й фосфатною групою. У переважній більшості випадків (окрім деяких вірусів, що містять одноланцюгові ДНК) макромолекула ДНК складається з двох ланцюгів, орієнтованих азотистими основами один проти одного. Ця дволанцюгова молекула утворює спіраль. У цілому структура молекули ДНК отримала назву «подвійної спіралі».
У ДНК зустрічається чотири види азотистих основ (аденін, гуанін, тимін і цитозин). Азотисті основи одного з ланцюгів сполучені з азотистими основами іншого ланцюга водневими зв'язками згідно з принципом комплементарності: аденін з'єднується тільки з тиміном, гуанін — тільки з цитозином.
Послідовність нуклеотидів дозволяє «кодувати» інформацію про різні типи РНК, найважливішими з яких є матричні (мРНК), рибосомні (рРНК) і транспортні (тРНК) та інші некодуючі РНК. Всі ці типи РНК синтезуються у процесі транскрипції на матриці ДНК, тобто шляхом копіювання послідовності ДНК у послідовність макромолекули РНК, за допомогою принципу комплементарності. Деякі види РНК, такі як мРНК, тРНК, рРНК за допомогою малих ядерних РНК беруть участь у біосинтезі білків (процесах транскрипції, сплайсингу і трансляції). Крім кодуючих послідовностей, ДНК клітини містить некодуючі послідовності, що виконують регуляторні та структурні завдання, або не виконують ніяких функцій.[1] Ділянки кодуючих послідовностей разом із регуляторними ділянками, називаються генами. Сукупність всіх генів, регуляторних послідовностей, некодуючих послідовностей, тобто вся нуклеотидна послідовність ДНК, незалежно від її функцій, утворює геном організму.
У геномах еукаріотів містяться також довгі послідовності без очевидної функції (некодуючі послідовності). Також у складі геному досить поширені генетичні паразити — транспозони та вірусні, або схожі на них, послідовності. Проте організм може використовувати транспозони для виконання певних завдань, також транспозони можуть впливати на еволюцію генів.[2]
Розшифровка структури ДНК, виконана в 1953 році, стала одною з поворотних віх в історії біології. За видатний внесок у це відкриття Френсісу Кріку, Джеймсу Ватсону і Морісу Вілкінсу була присуджена Нобелівська премія з фізіології або медицини 1962 року.
Хімічний склад ДНК ред.
ДНК є полімерною молекулою, що складається з великої кількості мономерів — нуклеотидів. Так в одній молекулі ДНК хромосоми 1 людини знаходиться близько 248.96 мільйонів пар нуклеотидів[3]
Нуклеотиди ред.





Дезоксирибонуклеїнова кислота є біополімером (поліаніоном), мономерами якого є нуклеотиди[4][5]. Кожен нуклеотид складається із залишку фосфорної кислоти, приєднаного за 5'-положенням до цукру дезоксирибози, до якого також через глікозидний зв'язок (C—N) за 1'-положенням приєднана одна з чотирьох азотистих основ. Саме наявність характерного цукру і складає одну з головних відмінностей між ДНК і РНК, зафіксовану в назвах цих нуклеїнових кислот (до складу РНК входить цукор рибоза)[6]. На малюнку показано чотири основи та один із нуклеотидів — дезоксаденозинмонофосфат, утворений приєднанням аденіну до дезоксирибози й фосфату.

Дезоксирибоза, що входить до складу молекули ДНК, знаходиться переважно в С2'-ендо конформації, на відміну від С3'-ендо конформації рибози в молекулах РНК: відсутність OH-групи у 2 положенні дезоксирибози робить С2'-ендо конформацію можливою. Це надає ДНК структурної міцності й ригідності, на відміну від молекули РНК.[7]
За структурою молекул азотисті основи, що входять до складу нуклеотидів, розділяють на дві групи: пуринові (аденін [A] і гуанін [G]), утворені сполученими п'яти- і шестичленним гетероциклами та піримідинові (цитозин [C] і тимін [T]) — утворені одним шестичленним гетероциклом[8].
Як виняток, наприклад, у бактеріофага PBS1, в ДНК зустрічається п'ятий тип основ — урацил (U), піримідинова основа, що зазвичай входить до складу РНК замість тиміну і відрізняється від тиміну відсутністю метильної групи на кільці[9]. Слід зазначити, що тимін і урацил не так строго пов'язані з ДНК і РНК відповідно, як це вважалося раніше. Так, після синтезу деяких молекул РНК значне число урацилів у цих молекулах метилюєтся за допомогою спеціальних ферментів, перетворюючись на тимін. Це відбувається в транспортних і рибосомних РНК[10].
Цукрофосфатний остов ред.

Нуклеотиди поєднанні між собою фосфатними групами. Фосфатні групи формують фосфодіестерні зв'язки між третім і п'ятим атомами вуглецю сусідніх молекул дезоксирибози, в результаті взаємодії між 3-гідроксильною групою (3-ОН) однієї молекули дезоксирибози та 5-фосфатною групою (5-РО3) іншої. Фосфатна група разом з залишком дезоксирибози формує так званий цукрофосфатний остов молекули. Від цього остову відходять залишки азотистих основ убік.
Асиметричні кінці ланцюга ДНК називаються 3' (читається три-штрих) і 5' (п'ять-штрих). Полярність ланцюга грає важливу роль при синтезі ДНК (подовження ланцюга можливе тільки шляхом приєднання нових нуклеотидів до вільного 3'-кінцю).
Хімічні модифікації ДНК ред.
Метилювання ДНК ред.

|

|

|
| Цитозин | 5-метилцитозин | тимін |
За певних умов основи ДНК піддаються хімічним модифікаціям, які можуть бути успадковані без заміни послідовності ДНК, і, таким чином, є частиною епігенетичного коду. Найпоширенішим і найкраще описаним механізмом хімічних модифікацій є метилювання основ ДНК, цитозину в еукаріотів і цитозину та аденіну у бактерій.
Метилювання ДНК виявлене у всіх клітинах еукаріотів, проте середній рівень метилювання відрізняється у різних організмів, так у нематоди Caenorhabditis elegans метилювання цитозину майже не спостерігається, а у хребетних виявлений високий рівень метилювання — до 1%[11]. Відомо, що рівень метилювання цитозину впливає на експресію генів: ділянки гетерохроматину (що характеризуються відсутністю або низьким рівнем транскрипції) корелюють із рівнем метилювання. Наприклад, метилювання цитозину з утворенням 5-Метилцитозину важливе для інактивації X-хромосоми[12]. Попри біологічну роль, 5-метилцитозин може спонтанно дезамінуватися, перетворюючись на тимін, тому метильований цитозин є джерелом підвищеного числа мутацій[13].
Крім контролю експресії генів та, в результаті, контролю клітинного циклу[14], бактерії використовують метилювання аденіну і цитозину для захисту проти патогенів у складі рестрикційно-модифікаційної системи.
Іншим добре описаним типом модифікацій основ є глікозилювання урацилу з утворенням «J-основи» в кінетопластидах[15].
Топологічна структура ДНК ред.
Подвійна спіраль ред.

Полімер ДНК має досить складну структуру. Нуклеотиди ковалентно сполучені між собою в довгі полінуклеотидні ланцюги. Ці ланцюги в переважній більшості випадків (окрім деяких вірусів, що мають одноланцюговий ДНК-геном), у свою чергу, попарно об'єднуються за допомогою водневих зв'язків у структуру, що отримала назву подвійної спіралі[16][6].
Як вже було сказано вище, у переважної більшості живих організмів ДНК складається не з одного, а з двох полінуклеотидних ланцюгів. Ці два довгі ланцюги закручені один навколо іншого у вигляді подвійної спіралі, що стабілізується водневими зв'язками, які утворюються між повернутими один до одного азотистими основами ланцюгів, що входять до неї. У природі ця спіраль зазвичай правозакручена. Напрями від 3'-кінця до 5'-кінця у двох ланцюгах, з яких складається молекула ДНК, протилежні (ланцюги «антипаралельні» один одному).
Ширина подвійної спіралі в її найпоширенішій B-формі становить від 22 до 24 Å, або 2,2 — 2,4 нм, а довжина кожного нуклеотиду 3,3 Å (0,33 нм)[17]. Довжина всієї молекули залежить від виду організму, та може складати від десятків мікрон у деяких вірусів до кількох метрів (в одній хромосомі) у деяких рослин. Подібно до того, як у гвинтових сходах збоку можна побачити сходинки, на подвійній спіралі ДНК в проміжках між фосфатним остовом молекули можна бачити ребра основ, кільця яких розташовані в площині, перпендикулярній до подовжньої осі макромолекули.

Подвійна спіраль ДНК має декілька параметрів конформації, які можна характеризувати:[18]
- шифт (англ. shift, Dx), слайд (англ. slide, Dy), райз (англ. rise, Dz) — характеризують зсув однієї пари основ відносно іншої без зміни куту площини пар основ, так, що вони залишаються паралельними;
- твіст (англ. twist, Ω), ролл (англ. roll, ρ), тилт (англ. tilt, τ) — характеризують повороти площин однієї пари основ відносно іншої;
Жолобки ред.

У подвійній спіралі розрізняють малий (12 Å) і великий (22 Å) жолобки[7] (борозенки)[19]. Білки, наприклад, фактори транскрипції, які приєднуються до певних послідовностей у дволанцюговій ДНК, зазвичай взаємодіють з краями основ у великому жолобку, де вони доступніші[20].
ДНК може мати триланцюгову форму[en] при утворенні зв'язків з третім ланцюгом ДНК (або РНК) у великому жолобку через формування окрім канонічних ватсон-кріківських пар, третю хугстинову водневу взаємодію[en].
Утворення зв'язків між основами ред.
Нуклеотиди протилежних ланцюгів ДНК формують зв'язки між собою. В основному це відбувається завдяки водневим зв'язкам протилежних залишків азотистих основ, звідси назва, пара основ (англ. base pares, скорочено bp). Основним і найрозповсюдженішим типом пар основ є Ватсон-Кріківські (назва походить від імен учених Френсіса Кріка та Джеймса Ватсона, див. п. Історія дослідження ДНК)
Ватсон-Кріківські пари основ ред.
Ватсон-Кріківські пари основ є найбільш поширеним типом формування пар основ між ланцюгами ДНК (та РНК) у природі.[21]
При традиційному Ватсон-Кріківському формуванні водневих зв'язків між нуклеотидами, кожна основа на одному з ланцюгів зв'язується з однією певною основою іншого ланцюгу. Таке специфічне зв'язування називається комплементарним. Пуринові основи комплементарні піримідиновим (тобто, здатні до утворення водневих зв'язків з ними): аденін утворює зв'язки тільки з тиміном, а цитозин — з гуаніном. У подвійній спіралі ланцюги також зв'язані за допомогою гідрофобної взаємодії та стекінгу, які не залежать від послідовності основ ДНК[22].
- Ватсон-Кріківські пари основ
-
 пара основ GC
пара основ GC -
 пара основ AT
пара основ AT


Комплементарність подвійної спіралі означає, що інформація, яка міститься в одному ланцюгу, міститься і в іншому ланцюгу. Оборотність і специфічність взаємодій між комплементарними парами основ важлива для реплікації ДНК і решти всіх функцій ДНК в живих організмах.
Оскільки водневі зв'язки нековалентні, вони легко розриваються і відновлюються. Ланцюги подвійної спіралі можуть розходитися як замок-змійка під дією ферментів (гелікази) або при високій температурі[23].
Різні пари основ утворюють різну кількість водневих зв'язків. Пари A-T зв'язані двома, G-C — трьома водневими зв'язками, тому на розрив пар GC потрібно більше енергії. Відсоток GC-пар і довжина молекули ДНК визначають кількість енергії, необхідної для дисоціації ланцюгів: довгі молекули ДНК з великим вмістом GC більш «тугоплавкі»[24].
Хугстинові пари основ ред.
Приблизно 3% клітинної ДНК формує дуже нетривалі Хугстинові пари[en] (названі на честь біохіміка Карста Хугстина[en]). Така пара формується при розвороті пурину навколо глікозидного зв'язку на 180°.[21] Хугстинові пари основ формуються при утворенні триланцюгових ДНК або при утворенні чотириланцюгової ділянки, так званого G-квадруплексу, або G4, при цьому така структура стабільна.[25]
-
 Ватсон-Кріківськи та Хугстинові пари основ
Ватсон-Кріківськи та Хугстинові пари основ -
 G-квадруплекс
G-квадруплекс


Синтетичні пари основ ред.
Синтетичні пари основ (англ. Unnatural base pairs, UBP) це такі нуклеотиди ДНК, що створені в лабораторії та не зустрічаються в природі.[26] Ці нуклеотиди формують додаткову, третю пару основ так, що вона розпізнається ДНК-залежною ДНК-полімеразою під час реплікації ДНК чи полімеразної ланцюгової рекації. UBP зазвичай позначаються символами X та Y, хоча хімічна їхня структура не закріплена і варіює від дослідження до дослідження. Відомі синтетичні нуклеотидні пари Ds–Px, d5SICS[en]–dNaM[en] та TPT3–NaM[27]
Альтернативні форми подвійної спіралі ред.
ДНК може існувати в кількох конформаціях. Нині ідентифіковано та описано такі: A-ДНК, B-ДНК, C-ДНК, D-ДНК[28], E-ДНК[29], H-ДНК[30], L-ДНК[28], P-ДНК[31] і Z-ДНК[32][33]. Проте тільки A-, B- і Z-форма ДНК спостерігалися в природних біологічних системах. Конформація, яку приймає ДНК, залежить від послідовності ДНК, величини та напрямку суперскрученості, хімічних модифікації основ і концентрації хімічних речовин у розчині, перш за все концентрацій іонів металів і поліамінів[34]. B-форма, описана вище, є найпоширенішою[35]. Альтернативні конформації подвійної спіралі відрізняються своєю геометрією та розмірами.
A-форма — ширша правостороння спіраль, з дрібнішою і ширшою малою борозенкою і вужчою і глибшою великою борозенкою. Ця форма зустрічається за нефізіологічними умовами в зневоднених зразках ДНК, крім того, вона, ймовірно, зустрічається в живих клітинах у гібридних комплексах ланцюгів ДНК і РНК, та в комплексах ферментної ДНК[36][37]. Сегменти ДНК із хімічно зміненими (метильованими) основами можуть проходити через більші конформаційні зміни та приймають Z-форму. Тут ланцюги закручуються в ліву подвійну спіраль, на відміну від правої спіралі B-форми[38]. Ці структури можуть розпізнаватися специфічними Z-ДНК-зв'язуючими білками й можуть бути залучені до регуляції транскрипції[39].
-
 У залежності від концентрації іонів і нуклеотидного складу молекули, подвійна спіраль ДНК у живих організмах існує в різних формах. На малюнку (зліва направо) представлені A-, B- і Z-форма
У залежності від концентрації іонів і нуклеотидного складу молекули, подвійна спіраль ДНК у живих організмах існує в різних формах. На малюнку (зліва направо) представлені A-, B- і Z-форма -

-
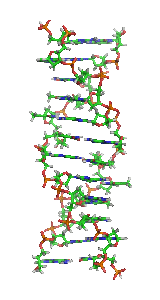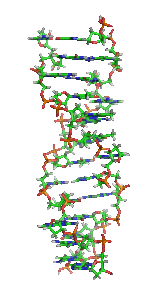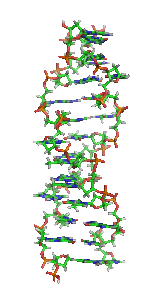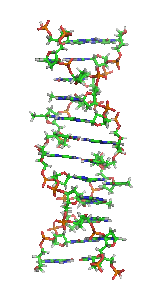 Візуалізація ДНК Z-форми
Візуалізація ДНК Z-форми



Просторова організація ДНК в клітинах ред.

ДНК більшості природних геномів має дволанцюгову структуру — або лінійну (в еукаріотів, деяких вірусів і окремих видів бактерій), або кільцеву (у більшості бактерій та архей, хлоропластів і мітохондрій). Лінійну одноланцюгову ДНК містять деякі віруси, у тому числі бактеріофаги.
ДНК бактерій та архей зазвичай представлена однією кільцевою молекулою ДНК, розташованою в цитоплазмі у вигляді утворення неправильної форми, що називається нуклеоїдом[40].
У клітинах еукаріотів ДНК розташовується головним чином в ядрі у вигляді набору хромосом. ДНК різних хромосом в ядрі не сильно перекручується, хромосоми займають певні об'єми ядра — хромосомні території[en].[41]
Одна молекула хромосомної ДНК набагато довша, ніж діаметр ядра клітини. Так у людини загальна теоретична довжина всіх ДНК хромосом складає 2 метри, тоді як середній діаметр ядра клітини — 6 мкм.[42] Тому в клітині ДНК щільно запакована за допомогою різних білків хроматину. Проте задля зчитування генів білкові комплекси повинні тимчасово від'єднатися від ділянок ДНК, в яких відбувається транскрипція, тому таке пакування ДНК в клітині є динамічним і чітко регульованим.[41]

Найменша структурна одиниця ДНК в клітині це ДНК, намотана на нуклеосому. Нуклеосома складається з восьми корових гістонів, довжина нуклеосомної ділянки ДНК складає 147 пар нуклеотидів. Для успішної реалізації генетичної інформації ДНК повинна від'єднатись від нуклеосоми, це може відбуватися АТФ-залежно за допомогою факторів, які беруть участь у транскрипції. Також модифікації частин нуклеосоми, гістонів, можуть ускладнювати чи полегшувати цей процес, що призводить до активації чи пригнічення активності генів (див. пункт Структурні та регуляторні білки та епігенетика)[43]
Вищий рівень організації геному включає взаємодію нуклеосоми з лінкерними гістонами, формуючи структуру під назвою хроматосома[44]
Доволі довгий час вважали, що хроматин далі формує специфічні структури, які мають назву 30-нм фібрили, яку можна було спостерігати в електронний мікроскоп in vitro. Проте на 2015 рік багато дослідників мають сумніви щодо існування 30-нм фібрили в живій клітині.[41]
Хроматин хребетних формує петлі, які дозволяють взаємодіяти лінійно далеким елементам ДНК, наприклад взаємодія енхансерів та промоторів. Довжина петель хроматину — тисячі нуклеотидів. Далі хроматин людини та миші, також частково D. melanogaster, формують ділянки великої кількості контактів всередині, розділені частинами хромосоми, які мало взаємодіють між собою. Такі ділянки називаються топологічно-асоційовані домени. Довжина ТАД від сотень тисяч до мільйонів пар основ. Вони бувають двох типів, A і B.[41]
Суперскрученість ред.
Якщо узятися за кінці мотузки й почати скручувати їх у різні боки, вона стає коротшою і на мотузці утворюються великі «супервитки». Також може бути суперскручена й ДНК. У звичайному стані ланцюжок ДНК робить один оберт на кожні 10,4 основи, але в суперскрученому стані спіраль може бути згорнута тугіше або розплетена[45]. Виділяють два типи суперскрученості: позитивну — у напрямі нормальних витків, при якому основи розташовані ближче одна до одної; і негативну — в протилежному напрямку. У природі молекули ДНК зазвичай перебувають в стані негативної суперскрученості, який вноситься ферментами, — топоізомеразами[46]. Ці ферменти вилучають додаткову скрученість, що виникає в ДНК в результаті транскрипції та реплікації[47].
Специфічні структури ред.
Теломера ред.

На кінцях лінійних хромосом є спеціалізовані структури ДНК, що називаються теломерами. Основна функція цих ділянок — підтримка цілісності кінців хромосом[48]. Звичайна довжина теломерної ділянки в геномі людини та миші — від 5 до 100 kb.[49]
Теломери захищають кінці ДНК від деградації екзонуклеазами та запобігають активації систем репарації, які запускаються у відповідь на розриви ДНК і формування хромосомних аберацій — дицентричних хромосом[50]. Оскільки звичайна ДНК-полімераза не може реплікувати 3'-кінці хромосом, спеціальний фермент — теломераза — після кожного поділу клітини подовжує теломери. При цьому як матриця для подовження ДНК використовується довга некодуюча РНК TERC[en]. Вкорочення теломер є однією з теоретичних причин старіння клітин (див. Межа Гейфліка).
- T-петля та D-петля
Послідовність теломер складається з декількох тисяч повторів шести нуклеотидів TTAGGG[51]. Ця структура закручується сама на себе, формуючи T-петлю, або теломерну петлю. 3'-кінець теломери має вигляд одноланцюгової ДНК завдовжки до декількох сотень нуклеотидів,[49] що приєднується до дволанцюгової ДНК. Це триланцюгове утворення називається D-петлею (від англ. displacement loop)[52].
Теломера зв'язана зі специфічними білковими структурами, такими як шелтерин[en].[49]
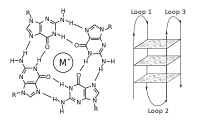
G-квадруплекс ред.

Послідовності з високим вмістом гуаніну стабілізують кінці хромосом, формуючи дуже незвичайні структури, які називають G-квадруплексами і які складаються з чотирьох, а не двох взаємодійних основ. Чотири гуанінових основи, всі атоми яких знаходяться в одній площині, утворюють пластинку, стабілізовану водневими зв'язками між основами та хелатованим у центрі іоном металу (найчастіше калію). Ці пластинки складаються стопкою одна над іншою[52].
G-квадруплекси можуть формувати теломерні ділянки, проте більшість G4 не знаходиться на теломерах. У клітинних лініях HaCaT знайдено близько 10000 G4, більшість з яких розташовані в вільних від нуклеосом ділянках які активно транскрибуються.[25] Біологічна роль G-квадруплеків не до кінця вивчена, проте формування таких структур може впливати на активність генів. Такі структури можуть запобігати проходженню ДНК-полімерази під час реплікації ДНК, що у свою чергу може призвести до пошкодження ДНК, тому для нормальної реплікації G-квадруплекси повинні бути "розкручені" спеціальними ферментами, хеліказами.[25]
Взаємодія з білками ред.

Всі функції ДНК залежать від її взаємодії з білками. Взаємодії можуть бути як неспецифічними, коли білок приєднується до будь-якої молекули ДНК, або залежати від наявності особливої послідовності. Ферменти також можуть взаємодіяти з ДНК. Найважливіші з них — полімерази, що копіюють послідовність основ ДНК на РНК у процесі транскрипції, а також на нову ДНК при синтезі нового ланцюга — реплікації.
Структурні і регуляторні білки ред.
Хроматин ред.
У клітинах ДНК не перебуває у вільному вигляді, натомість вона зв'язана зі структурними білками, утворюючи компактну структуру — хроматин. У випадку еукаріотів та багатьох архей хроматин утворюється за допомогою невеликих лужних білків — гістонів. У решти архей та бактерій ДНК менш щільно упакована за допомогою ряду інших білків, хоча серед них і знайдені гомологічні гістонам білки[54][55][56][57].
Гістони формують кулясті білкові структури — нуклеосоми, навколо кожної з яких вміщається два оберти спіралі ДНК з 147 нуклеотидів. Тобто одна молекула ДНК буде взаємодіяти з великою кількістю нуклеосом, це допомагає компактизвувати ДНК, що часто має розміри на декілька порядків довші, ніж діаметр клітини, у клітинне ядро (див. п. Просторова організація ДНК в клітинах)[58]. Зв'язки між гістонами та ДНК не залежать від конкретної послідовності нуклеотидів ДНК, і утворюються за рахунок іонних зв'язків лужних амінокислот гістонів і кислотних залишків цукрофосфатного остову ДНК[59]. Хімічні модифікації цих амінокислот включають метилювання, фосфорилювання і ацетилювання[60]. Ці хімічні модифікації змінюють силу взаємодії між ДНК і гістонами, впливаючи на доступність специфічних послідовностей для факторів транскрипції і змінюючи швидкість транскрипції[61]. Нуклеосоми повинні бути від'єднані від молекули ДНК для проходження транскрипції та реплікації. У тих генів, які мають високий рівень транскрипції, їхні регуляторні ділянки на початку гена — промотори — часто мають вільну від нуклеосом ділянку (англ. nucleosome-free region, NFR)[41][62]
Інші білки у складі хроматину, які приєднуються до неспецифічних послідовностей, — білки з високою рухливістю в гелях, що асоціюють переважно із зігнутою ДНК[63]. Ці білки важливі для утворення в хроматині структур вищого порядку[64].

У сперматозоїдах тварин переважна більшість гістонових білків замінюється на протаміни під час сперматогенезу, це дозволяє щільніше запакувати ДНК в ядрі сперматозоїда. Протаміни та ДНК формують тороїдно-подібні структури, діаметром 50-100 нм.[65]
Фактори транскрипції та інші білки ред.
Особлива група білків, що приєднуються до ДНК, — білки, які асоціюють з одноланцюговою ДНК. Найкраще охарактеризований білок цієї групи у людини — реплікаційний білок А, без якого неможливе протікання більшості процесів, де розплітається подвійна спіраль, включаючи реплікацію, рекомбінацію і репарацію ДНК. Білки цієї групи стабілізують одноланцюгову ДНК і запобігають формуванню стебел-петель або деградації ДНК нуклеазами[66].
Водночас інші білки розпізнають специфічні послідовності й приєднуються до них. Найбільш вивчена група таких білків — різні класи факторів транскрипції, тобто білки, що регулюють транскрипцію. Кожен з цих білків розпізнає свою послідовність, часто в промоторі, й активує або пригнічує транскрипцію гену. Це відбувається при асоціації факторів транскрипції з РНК-полімеразою або безпосередньо, або через білки-посередники. Полімераза асоціює спочатку з білками, а потім починає транскрипцію[67]. В інших випадках фактори транскрипції можуть приєднуватися до ферментів, які модифікують гістони, що знаходяться на промоторах, і, таким чином, змінюють доступність ДНК для полімераз[68].
Оскільки специфічні послідовності зустрічаються в багатьох місцях геному, зміни в активності одного типу факторів транскрипції можуть змінити активність тисяч генів[69]. Відповідно, ці білки часто регулюються в процесах відповіді на зміни в навколишньому середовищі, розвитку організму і диференціацію клітин. Специфічність взаємодії факторів транскрипції з ДНК забезпечується численними контактами між амінокислотами і основами ДНК, що дозволяє їм «читати» послідовність ДНК. Більшість контактів з основами відбуваються в головній борозенці, де основи доступніші.[20]
Ферменти, що модифікують ДНК ред.
Топоізомерази і гелікази ред.
У клітині ДНК перебуває в суперскрученому стані, що дозволяє їй досягти компактнішої організації. Для протікання багатьох процесів життєдіяльності ДНК повинна бути розкручена, що виконується двома групами білків — топоізомеразами і геліказами.
Топоізомерази — ферменти, які мають як нуклеазну, так і лігазну активності. Ці білки змінюють топологію, зокрема ступінь суперскрученості ДНК. Деякі з цих ферментів розрізають подвійну спіраль ДНК і дозволяють обертатися одному з ланцюгів, тим самим зменшуючи рівень суперскрученості, після чого фермент заклеює розрив[46]. Інші ферменти можуть розрізати один з ланцюгів і проводити другий ланцюжок через розрив, а потім лігувати розрив в першому ланцюгу[70]. Топоізомерази необхідні в багатьох процесах, пов'язаних з ДНК, таких як реплікація і транкрипція[47].
Гелікази — білки, що належать до молекулярних моторів. Вони використовують хімічну енергію нуклеозидтрифосфатів, найчастіше АТФ, для розриву водневих зв'язків між основами, розкручуючи подвійну спіраль на окремі ланцюги[71]. Ці ферменти важливі для більшості процесів, де білкам необхідний доступ до основ ДНК.
Нуклеази і лігази ред.

У різних процесах, що відбуваються в клітині, наприклад, рекомбінації і репарації, беруть участь ферменти, здатні розрізати і відновлювати цілісність ланцюгів ДНК. Ферменти, що розрізають ДНК, називаються нуклеазами. Нуклеази, які гідролізують нуклеотиди на кінцях молекули ДНК, називаються екзонуклеазами, а нуклеази, що розрізають ДНК усередині ланцюга — ендонуклеазами. Нуклеази, що найчастіше використовуються в молекулярній біології і генетичній інженерії, входять до класу рестриктаз, які розрізають ДНК біля специфічних послідовностей. Наприклад, фермент EcoRV (рестрикційний фермент № 5 бактерії E. coli) розпізнає шестинуклеотидну послідовність 5'-GAT|ATC-3' й розрізає ДНК у місці, вказаному вертикальною лінією. У природі ці ферменти захищають бактерії від зараження бактеріофагами, розрізаючи ДНК фага, коли вона вводиться в клітину бактерії. Власна ДНК бактерії захищена від рестриктаз за допомогою метилювання. У цьому випадку нуклеази — частина рестрикційно-модифікаційної системи[72].
ДНК-лігази зшивають цукрофосфатні остови молекул ДНК, використовуючи енергію АТФ. Вони особливо важливі в процесах реплікації ланцюга, що запізнюється, з'єднуючи між собою фрагменти Окадзакі. Крім того, вони використовуються в репарації ДНК і гомологічній рекомбінації[73]. У лабораторних дослідженнях лігази широко використовуються в клонуванні і фінґерпринтингу.
Полімерази ред.
Інша важлива для метаболізму ДНК група ферментів — полімерази — синтезують ланцюги полінуклеотидів з нуклеозидтрифосфатів. Вони додають нуклеотиди до 3'-гідроксильної групи попереднього нуклеотиду в ланцюгу ДНК, тому всі полімерази працюють у напрямі 5' → 3'[74][75]. У активному центрі цих ферментів субстрат — нуклеозидтрифосфат — злучається з комплементарною основою у складі одноланцюгового полінуклеотидного ланцюга — матриці.
У залежності від матриці, яку використовує полімераза, та від продукту, який вона синтезує, полімерази ділять на декілька типів.
- ДНК-залежна ДНК-полімераза
У процесі реплікації ДНК ДНК-залежна ДНК-полімераза синтезує копію початкової послідовності ДНК. У цьому процесі дуже важлива точність, оскільки помилки полімеризації приведуть до мутацій, тому багато полімераз мають здатність до «редагування» — виправлення помилок. Полімераза дізнається про помилки в синтезі за відсутністю спаровування між неправильними нуклеотидами. Після визначення відсутності спаровування активується 3' → 5'-екзонуклеазна активність полімерази й неправильна основа вилучається[76]. У більшості організмів ДНК-полімерази працюють у вигляді великого комплексу, що в бактерій називається реплісомою. Вона містить численні додаткові субодиниці, наприклад, гелікази[77].
- РНК-залежна ДНК-полімераза
РНК-залежні ДНК-полімерази (зворотні транскриптази) — спеціалізований тип полімераз, які копіюють послідовність РНК на ДНК. До цього класу ферментів належить вірусна зворотна транскриптаза, яка використовується ретровірусами при інфекції клітин, а також теломераза, необхідна для реплікації теломер, та фермент зворотної транскриптази деяких трансозонів[78]. Теломераза — РНК-білковий комплекс, що містить власну матричну РНК, яка й використовується для зворотної транскрипції[50].
- ДНК-залежна РНК-полімераза
Транскрипція здійснюється ДНК-залежною РНК-полімеразою, яка копіює послідовність ДНК одного ланцюга на мРНК. На початку транскрипції гену РНК-полімераза приєднується до послідовності на початку гена, промотором, і розплітає спіраль ДНК. Потім вона копіює послідовність гену на матричну РНК доти, доки не дійде до ділянки ДНК в кінці гена — термінатора, де вона зупиняється і від'єднується від ДНК. Окрім того, ДНК-залежна ДНК-полімераза людини, РНК-полімераза II, яка транскрибує більшу частину генів людини, працює у складі великого білкового комплексу, що містить регуляторні й додаткові субодиниці[79].
Біологічні властивості ДНК ред.
ДНК є носієм генетичної інформації, записаної у вигляді нуклеотидної послідовності за допомогою генетичного коду. З молекулами ДНК зв'язані дві основні властивості живих організмів — спадковість і мінливість. У ході процесу, що називається реплікацією ДНК, з початкового, материнського, ланцюга, утворюються дві копії ДНК, які успадковуються дочірніми клітинами при поділі. Клітини, що утворилися таким чином, будуть генетично ідентичними. Потрібна для клітинної життєдіяльності генетична інформація зчитується при експресії генів. У багатьох випадках вона використовується для біосинтезу білків у процесах транскрипції (синтезу молекул РНК на матриці ДНК) і трансляції (синтезу білків на матриці РНК).
Послідовність нуклеотидів «кодує» інформацію про різні типи РНК: кодуючі — матричні (мРНК) — та некодуючі — рибосомні (рРНК), транспортні (тРНК), каталітичні та інші. Всі ці типи РНК синтезуються на основі ДНК у процесі транскрипції. Їхня роль у біосинтезі білків та інших процесах життєдіяльності клітини різна. Матрична РНК містить інформацію про послідовність амінокислот у білку, рибосомальні РНК служать основою для рибосом (складних нуклеопротеїнових комплексів, основна функція яких — збірка білка з окремих амінокислот на основі мРНК), транспортні РНК доставляють амінокислоти до місця збірки білків — в активний центр рибосоми, що рухається по мРНК, проте синтезуються також некодуючі РНК, які можуть виконувати різноманітні регуляторні функції.
Реплікація ред.

Поділ клітини необхідний для розмноження одноклітинних і росту багатоклітинних організмів, але до поділу клітина повинна подвоїти геном, щоб дочірні клітини містили ту ж генетичну інформацію, що і початкова клітина. ДНК подвоюється у процесі реплікації[80], що протікає за напівконсервативним механізмом: два ланцюги розділяються, і потім кожна комплементарна послідовність ДНК відтворює для себе пару за допомогою ферменту ДНК-полімераза. Цей фермент будує полінуклеотидний ланцюжок, знаходячи правильний нуклеотид через комплементарне спаровування основ і приєднуючи його до зростаючого ланцюга. ДНК-полімераза, що здійснює більшу частину синтезу (Pol III прокаріотів або Pol δ еукаріотів) не може розпочати синтез нового ланцюга, а тільки нарощує вже існуючий, тому вона потребує наявності праймерів, ділянок ДНК, синтезованих за допомогою спеціальної РНК-полімерази праймази. Оскільки ДНК-полімерази можуть будувати ланцюжок тільки у напрямку 5' → 3', для копіювання антипаралельних ланцюгів використовуються складні механізми з залученням великої кількості білків[81], і цей ланцюг копіюється переривчасто, невеликими ділянками — фрагментами Окадзакі, довжиною близько 200 bp.[82]
Генетична рекомбінація ред.

Подвійна спіраль ДНК зазвичай не взаємодіє з іншими сегментами ДНК, а в клітинах еукаріотів різні хромосоми просторово розділені в ядрі[83] і займають свої хромосомні території. Проте в певні періоди клітинного циклу (мейоз або репарація) гомологічні хромосоми можуть обмінюватися нуклеотидними послідовностями.
У процесі рекомбінації дві спіралі ДНК розриваються, після чого безперервність спіралей відновлюється, але не обов'язково в правильному порядку, тому обмін ділянками хромосом може привести до пошкодження цілісності генетичного матеріалу. З іншого боку, рекомбінація дозволяє хромосомам обмінюватися генетичною інформацією, в результаті цього утворюються нові комбінації генів, що збільшує ефективність природного добору й важливо для швидкої еволюції нових білків[84].
У процесі негомологічної рекомбінації (негомологічного з'єднання кінців), що виникає в результаті зовнішніх пошкоджень, дві спіралі ДНК розриваються, після чого неперервність спіралей відновлюється в процесі репарації клітиною дволанцюгових розривів ДНК[85], але не обов'язково в правильному порядку. Тому обмін ділянками негомологічних хромосом може привести до пошкодження цілісності генетичного матеріалу в результаті розриву генів або розриву регуляторних зв'язків — транслокацій.
Найпоширеніша форма рекомбінації — гомологічна рекомбінація — коли рекомбінація виникає між гомологічними хромосомами, тобто хромосомами, що мають дуже схожі послідовності (що зазвичай утворюються в організмах зі статевим розмноженням під час мейозу). Іноді як гомологічні ділянки виступають транспозони. Реакція гомологічної рекомбінації каталізується ферментами, які називаються рекомбіназами, наприклад, Cre. На першому етапі реакції рекомбіназа робить розрив в одному з ланцюгів ДНК, дозволяючи цьому ланцюгу відокремитися від комплементарного ланцюга й приєднається до одного з ланцюгів другої хроматиди. Інший розрив в ланцюгу другої хроматиди дозволяє їй також відокремитися і приєднається до ланцюга, що залишився без пари, з першої хроматиди, формуючи структуру Холідея. Структура Холідея може пересуватися вздовж сполученої пари хромосом, міняючи ланцюги місцями. Реакція рекомбінації завершується, коли фермент розрізає з'єднання, а два ланцюги лігуються[86].
Пошкодження ДНК ред.

ДНК може пошкоджуватись різноманітними мутагенами, до яких належать окиснюючі й алкілюючі речовини, а також високоенергетична електромагнітна радіація — ультрафіолетове й рентгенівське випромінювання. Тип пошкодження ДНК залежить від типу мутагена. Наприклад, ультрафіолет пошкоджує ДНК шляхом появи в ній димерів тиміну, які утворюються при формуванні ковалентних зв'язків між сусідніми основами[88].
Активні форми кисню, наприклад «вільні» радикали або перекис водню призводять до кількох типів пошкодження ДНК, включаючи модифікації основ, особливо гуанозину, а також дволанцюгові розриви в ДНК[89]. За деякими оцінками у кожній клітині людини близько 500 основ пошкоджуються окислюючими сполуками щодня[90][91]. Серед різних типів пошкоджень найнебезпечніші — дволанцюгові розриви, тому що вони важко репаруються і можуть призвести до втрат ділянок хромосом (делецій) і транслокацій.
Багато молекул мутагенів вставляються (інтеркалюються) між двома сусідніми парами основ. Більшість цих сполук, наприклад, бромистий етидій, даунорубіцин, доксорубіцин і талідомід, мають ароматичну структуру. Для того, щоб ароматична сполука могла вміститися між основами, вони повинні розійтися, розплітаючи й порушуючи структуру подвійної спіралі. Ці зміни в структурі ДНК перешкоджають транскрипції і реплікації, викликаючи мутації. Тому інтеркалюючі речовини часто є канцерогенами, найвідоміші з яких — бензопірен, акридини, афлатоксини і бромистий етидій[92][93][94], хоча прямих доказів мутагенної дії на людину від бромистого етидію не знайдено,[95] тому це питання залишається контраверсійним. Попри ці негативні властивості, в силу своєї здатності пригнічувати транскрипцію і реплікацію ДНК, деякі речовини, що інтеркалюють до ДНК, використовуються в хіміотерапії для пригнічення швидкого росту ракових клітин[96].
Виправлення пошкодження ДНК ред.
Прокаріоти і ядерні організми мають системи виправлення пошкоджень молекули ДНК. У залежності від типу пошкоджень, репарація може бути дволанцюгових чи одноланцюгових розривів ДНК, чи вилучення неправильного, некомплементарного нуклеотиду з одного ланцюга і заміщення його комплементарним. [97]
Біологічні ролі ДНК ред.
Функціональна послідовність ДНК ред.
Генетична інформація геному складається з генів. Ген — одиниця передачі спадковій інформації, що має вигляд безперервної ділянки ДНК і впливає на певну характеристику організму. Білок-кодуючі гени містять відкриту рамку зчитування, яка транскрибуєтся, а також регуляторні послідовності, наприклад, промотори і енхансери, які контролюють експресію генів. Некодуючі РНК відкритих рамок зчитування переважно не мають, проте регуляторні послідовності в них є.
У багатьох організмах тільки мала частина загальної послідовності геному кодує білки. Так тільки близько 1,5% геному людини складається з екзонів, що кодують білок, а понад 50% ДНК складається з повторюваних некодуючих послідовностей ДНК, таких як Alu-повтори[98]. Причини існування такої великої кількості некодуючої ДНК в еукаріотичних геномах і величезна різниця в розмірах геномів (C-значення) — одна з нерозв'язаних наукових загадок[99].
Послідовності геному, що не кодують білок ред.
Традиційно некодуючі послідовності ДНК, за винятком промоторів, що безпосередньо передують відкритим рамкам зчитування, розглядалися як «сміттєва ДНК» (англ. junk DNA). Проте тепер накопичується дедалі більше даних, що суперечать цій ідеї й свідчать про різноманітні корисні функції цих послідовностей. Теломери і центромери містять мале число генів, але вони важливі для функціонування і стабільності хромосом[50][100]. Розповсюджена форма некодуючих послідовностей людини — псевдогени, копії генів, інактивовані в результаті мутацій[101]. Ці послідовності є чимось подібним до молекулярних скам'янілостей, хоча іноді вони можуть слугувати початковим матеріалом для дуплікації і подальшої дивергенції генів[102].
Інший тип некодуючої ДНК, що однак транскрибується в РНК — інтрони. Інтрони також є джерелом різноманітності білків в організмі, бо можуть використовуватися як «лінії розрізу і склеювання» при альтернативному сплайсингу[103]. Нарешті, послідовності ДНК, що не кодують білок, можуть кодувати допоміжні клітинні РНК, наприклад малі ядерні РНК[104].
Проєкт Енциклопедії елементів ДНК призначений для встановлення відсотку транскрипції геному та ролі транскрибованих з нього продуктів. За даними ENCODE 2012, у людини приблизно 20,5 тисяч білок-кодуючих генів, що закодовані у 2,94% геному, але якщо брати лише екзони, то ця цифра буде 1,22%. Разом з тим було знайдено майже 9 тисяч малих РНК та близько 9,5 тисяч довгих некодуючих РНК та трохи більше 11 тисяч псевдогенів.[105]
Транскрипція і трансляція ред.
Генетична інформація, закодована в ДНК, повинна бути прочитана і зрештою виражена в синтезі різних біополімерів, з яких складаються клітини. Послідовність основ у ланцюгу ДНК безпосередньо визначає послідовність основ у РНК, на яку вона «переписується» в процесі, що називається транскрипцією.
У випадку мРНК послідовність нуклеотидів визначає амінокислоти білка. Співвідношення між нуклеотидною послідовністю мРНК і амінокислотною послідовністю білків визначається правилами трансляції, які називаються генетичним кодом. Генетичний код складається із кодонів, тринуклеотидних послідовностей (наприклад АСТ, CAG, ТТТ тощо), що безпосередньо слідують одна за одною.
Під час транскрипції нуклеотиди гену копіюються на РНК, що синтезується РНК-полімеразою. Ця копія у разі мРНК декодується рибосомою, яка «зчитує» послідовність мРНК, здійснюючи спаровування матричної РНК з ділянками транспортних РНК, комплексів РНК і амінокислот у процесі трансляції. Оскільки в тринуклеотидних комбінаціях використовуються 4 основи, всього можливі 64 кодони (43 комбінації). Кодони кодують 20 стандартних амінокислот, кожній з яких у більшості випадків відповідає більш ніж один кодон. Один з трьох кодонів, які розташовуються в кінці мРНК, не кодує амінокислоту і визначає кінець білка. Це стоп- або нонсенс-кодони (у більшості організмів — TAA, TGA, TAG).
З ДНК також зчитуються різні некодуючі РНК — молекули, нуклеотидна послідовність яких не буде переведена в амінокислотну послідовність білків. Такі нкРНК можуть виконувати в клітині різноманітні функції, включаючи участь у біосинтезі білків, трансляції, регуляції експресії генів, топологічної організації геномної ДНК тощо.[106]
Еволюція метаболізму ДНК ред.
ДНК містить генетичну інформацію, яка робить можливою життєдіяльність, ріст, розвиток і розмноження всіх сучасних організмів. Проте невідомо протягом якого часу з чотирьох мільярдів років історії життя на Землі ДНК була головним носієм генетичної інформації. Існують гіпотези, що РНК грала центральну роль в обміні речовин, оскільки вона може як переносити генетичну інформацію, так і здійснювати каталіз за допомогою рибозимів[107][108][109]. Крім того, РНК — один із основних компонентів «фабрик білка» — рибосом. Стародавній РНК-світ, де нуклеїнова кислота використовувалася і для каталізу і для перенесення інформації, міг послужити зародком сучасного генетичного коду, що складається з чотирьох основ. Це могло відбутися в результаті того, що число основ в організмі було компромісом між невеликим, що збільшувало точність реплікації, й великим, що збільшувало каталітичну активність рибозимів[110].
На жаль, стародавні генетичні системи не дожили до наших днів. ДНК в найкращих умовах навколишнього середовища зберігається протягом 1 мільйона років, а потім деградує до коротких фрагментів. Отримання ДНК й визначення послідовності генів 16S рРНК з комах, загрузлих в бурштині, який утворився 250 млн років тому, та бактеріальних спор[111] служить темою жвавої дискусії в наукових колах[112][113]. Проте дослідження вказують на те, що навіть за оптимальних умов замороження до -5 C° і перебування в такому стані, кожен зв'язок в молекулі ДНК зруйнується після 6,8 мільйонів років. Проте інформація, яку можна взяти з послідовності ДНК, перестане бути доступною за значно коротший період у 1,5 мільйонів, оскільки за цей період ДНК зруйнується до надто коротких фрагментів. Цього періоду недостатньо навіть для визначення послідовності ДНК динозаврів, які жили мінімум 65 мільйонів років тому[114]
Використання ДНК в технології ред.

Методи роботи з ДНК ред.
З розвитком молекулярної біології було розроблено багато методів роботи з ДНК. Ці методи перш за все включають виділення ДНК, зазвичай за допомогою руйнування клітин, що містять необхідну ДНК, та спиртової преципітації ДНК з розчину. При необхідності ДНК очищують за допомогою адсорбційної хроматографії. Більші кількості ДНК можна одержати за допомогою полімеразної ланцюгової реакції (ПЛР), що вимагає лише кількох молекул ДНК, але дозволяє ампліфікувати лише відносно невеликі ділянки ДНК, зазвичай до 1500 bp, або молекулярного клонування для ділянок більшої довжини.
Отримана ДНК може бути проаналізована за допомогою рестрикційного аналізу, тобто розрізання ДНК на певних ділянках за допомогою рестриктаз, та розділення отриманих фрагментів за допомогою гелевого електрофорезу, а потім, якщо необхідно, їхньої візуалізації за допомогою саузерн-блоту. У деяких випадках можливий одночасний аналіз цілих геномів, для чого використовуються ДНК-мікрочипи, тобто матриці, на які нанесені флюоресцентно мічені комплементарні ДНК, що дозволяє проведення порівняльної гібридизації геномів та аналіз рівня експресії багатьох генів одночасно (хоча в останньому випадку мова йде про детекцію РНК, а не ДНК).
Ще одним з поширених методів роботи з ДНК є секвенування, тобто встановлення її нуклеотидної послідовності. Численні проєкти секвенування та аналізу ДНК в останні роки 20-го століття та на початку 21-го привели до встановлення послідовностей та опису геномів багатьох організмів всіх головних таксономічних груп. Найбільшим та найвідомішим з них став проєкт геному людини. Тоді як проєкт ENCODE (Енциклопедія елементів ДНК) спрямований на встановлення функцій різних ділянок ДНК геному людини. Функціями мишачого геному займається mouse ENCODE. [115]
У випадках, коли досліджується експресія генів, з клітин виділяють не ДНК, а РНК, яка потім за допомогою зворотної транскрибції переводиться у кДНК. Найбільш уживані методи для вивчення рівня експресії генів це qПЛР
Генна інженерія ред.
Сучасні біологія і біохімія інтенсивно використовують методи, засновані на рекомбінантній ДНК. Рекомбінантна ДНК — штучно створена послідовність ДНК, частини якої можуть бути синтезовані хімічним шляхом, за допомогою ПЛР, або клонуванні з ДНК різних організмів. Рекомбінантні ДНК можуть бути трансформовані в клітини живих організмів у складі плазмід або вірусних векторів[116]. Генетично модифіковані тварини і рослини зазвичай містять рекомбінантні гени, вбудовані в їхні хромосоми. Тоді як генетично модифіковані бактерії і дріжджі використовуються для виробництва рекомбінантних білків, тварини використовуються в медичних дослідженнях[117], а рослини з покращеними харчовими якостями — в сільському господарстві[118][119].
Судово-медична експертиза ред.

Судмедексперти використовують знайдені на місці злочину ДНК крові, сперми, шкіри, слини або волосся для ідентифікації злочинця. Процес ідентифікації називається генетичним фінґерпринтингом або визначенням картини (профайлу) ДНК. У фінґерпринтингу порівнюється варіабельні ДНК геному, наприклад, тандемні повтори: мікросателіти й мінісателіти різних людей. Це надійний метод визначення особистості[120], хоча визначення може бути утруднене при забрудненні сцени злочину ДНК інших людей[121].
Фінґерпринтинг був розроблений в 1984 році британським генетиком Алеком Джеффрейсом (Alec Jeffreys)[122] і вперше використаний як доказ у суді над Коліном Пітчфорком (Colin Pitchfork) в справі, де він був звинувачений у вбивстві й зґвалтуванні[123].
Наразі в багатьох західних країнах, наприклад, Великій Британії і США, у злочинців, звинувачених у злочинах деяких типів, забирається зразок ДНК для бази даних. Це допомогло визначити винних в раніше нерозкритих злочинах, оскільки ДНК зберігається на речових доказах. Ще цей метод використовується для визначення особи у разі масової загибелі людей[124] та багатьох інших тестах.
Також метод генетичного фінґерпринтингу використовується для проведення тесту на батьківство, встановлення відповідності донорських органів, діагностики генетичних хвороб та дослідження популяцій тварин.
Біоінформатика ред.
Біоінформатика включає обробку даних (data mining), що міститься в послідовності ДНК. Розвиток комп'ютерних методів зберігання і пошуку такої інформації привів до розвитку таких напрямів інформатики, що знайшли й інше застосування, як SSA (string searching algorithm), машинне навчання і організація баз даних[125]. Алгоритми типу ССА, які шукають певну послідовність «букв» у більшій послідовності букв, були розроблені для пошуку специфічних послідовностей нуклеотидів[126]. В інших комп'ютерних застосуваннях, наприклад, текстових редакторах найпростіші алгоритми справляються з цим завданням, але прогляд послідовності ДНК належить до складних задач, тому що вони дуже великі й складаються всього з чотирьох букв. Схожа проблема виникає при порівнянні послідовностей із різних організмів (sequence alignment), яке використовується у вивченні філогенетичних взаємин між цими організмами й функцій білків[127]. Дані про послідовність цілих геномів, одним з найскладнішим з яких є геном людини, важко використовувати без опису, що вказує на положення генів і регуляторних послідовностей на кожній хромосомі. Ділянки ДНК, послідовності якої містять фрагменти, асоційовані з генами, що кодують білки або РНК, можуть бути знайдені за допомогою спеціальних алгоритмів, які дозволяють передбачити наявність продуктів експресії генів до їхнього виявлення в результаті експериментів[128].

ДНК і комп'ютери нового покоління ред.
ДНК вперше була використана в обчислювальній техніці для розв'язку задачі пошуку гамільтонового шляху, окремого випадку NP-повної задачі[129]. ДНК-комп'ютер має переваги над електронними комп'ютерами, оскільки теоретично вимагає менше енергії, займає менше місця і ефективніший завдяки можливості одночасних підрахунків (див. Паралельні обчислення). Інші задачі, наприклад, задача автоматів, задача здійсненності бульових формул і варіант задачі комівояжера були проаналізовані за допомогою ДНК-комп'ютерів[130]. Завдяки компактності ДНК вона теоретично може знайти застосування в криптографії, де може використовуватися для конструювання одноразових шифроблокнотів[131].
Історія і антропологія ред.
Оскільки з часом в ДНК накопичуються мутації, які потім передаються у спадок, вона містить історичну інформацію, тож генетики можуть досліджувати еволюційну історію організмів (філогенетику)[132].
Філогенетика — метод еволюційної біології. Якщо порівнюються послідовності ДНК усередині виду, еволюційні генетики можуть довідатися історію окремих популяцій. Ця інформація може бути корисною в різних галузях науки, починаючи з екологічної генетики й закінчуючи антропологією. Наприклад, при дослідженні як мітохондріальної, так і ядерної ДНК твердих тканин (зубів та кісток) мумій було встановлено, що стародавні Єгиптяни більш споріднені до стародавніх Європейців ніж до сучасних Єгиптян. Їхні найближчі родичі проживали в місцевості Левант під час неоліту та бронзової доби.[133]
Іншим прикладом використання послідовності ДНК для встановлення еволюції людини може бути аналіз неандертальського геному і встановлення, що впродовж історії неандертальці парувалися з H. sapiens[134]
ДНК у культурі ред.

Структура молекули ДНК була відкрита у 1953 році та з того часу надихала художників і скульпторів своєю оригінальною формою. На честь подвійної спіралі ДНК побудовано декілька скульптур в рамках проєкту американського скульптора Чарлза Дженкса[en], зокрема встановлена на Кембриджських скульптурних стежках[de] у кампусі Кембриджського університету 2005 року «Подвійна спіраль ДНК».[135] Уособлює подвійну спіраль також Міст Подвійної спіралі у Сінгапурі, відкритий 2010 року.[136] 50-річчю відкриття структури ДНК присвячена 2-фунтова монета Великої Британії авторства скульптора Джона Міллза[en], викарбувана 2003 року.[137]
Прочитання послідовності ДНК людини та інших організмів призвело до появи інструментів, які представляють запис нуклеотидів у вигляді нот, створюючи музичні композиції.[138][139]
Історія дослідження ДНК ред.

ДНК була відкрита Іоганном Фрідріхом Мішером у 1869 році. Спочатку нова речовина отримала назву «нуклеїн», а пізніше, коли Мішер виявив у неї кислотні властивості, її назвали нуклеїновою кислотою[140]. Біологічна функція нововідкритої речовини була неясна, і довгий час ДНК вважалася запасником фосфору в організмі. Більш того, навіть на початку 20 століття багато біологів вважали, що ДНК не має стосунку до передачі інформації, оскільки будова молекули, на їхню думку, була дуже одноманітною і не могла містити закодовану інформацію.
Поступово було доведено, що саме ДНК, а не білки, як вважалося раніше, є носієм генетичної інформації. Одними з перших вирішальних доказів стали експерименти О. Евері, Коліна Мак-Леода і Маклін Мак-Карті (1944 рік) з трансформації бактерій. Їм вдалося показати, що за так звану трансформацію (придбання хвороботворних властивостей нешкідливою культурою у результаті додавання до неї мертвих хвороботворних бактерій) відповідає виділена з пневмококів ДНК. Експеримент американських учених Алфреда Хершу і Марти Чейз (1952 рік) з міченими радіоактивними ізотопами білками і ДНК бактеріофагів показали, що в заражену клітину передається тільки нуклеїнова кислота фага, а нове покоління фага містить такі ж білки і нуклеїнову кислоту, як і початковий фаг[141].
До 50-х років 20 століття точна будова ДНК, як і спосіб передачі спадкової інформації, залишалася невідомою. Хоч і було напевно відомо, що ДНК складається з кількох ланцюгів, що своєю чергою складаються з нуклеотидів, ніхто не знав точно, скільки цих ланцюгів і як вони сполучені.
Структура подвійної спіралі ДНК була запропонована Френсісом Кріком і Джеймсом Ватсоном у 1953 році на основі рентгеноструктурних даних, отриманих Морісом Вілкінсом і Розаліндою Франклін, і «правил Чаргаффа», згідно з якими в кожній молекулі ДНК дотримуються строгі співвідношення, що зв'язують між собою кількість азотистих основ різних типів[16]. Пізніше запропонована Ватсоном і Кріком модель будови ДНК була доведена, а їхня робота відмічена Нобелівською премією з фізіології і медицини 1962 року. Серед одержувачів не було Розалінди Франклін, що померла на той час, оскільки премія не присуджується посмертно[142].
У відомій доповіді 1957 року Крік окреслив основи так званої «Центральної догми» молекулярної біології, яка передбачає взаємовідношення між ДНК, РНК і білками, та сформулював «адаптерну гіпотезу»[143]. Остаточне підтвердження механізму копіювання, запропонованого на основі спіральної структури, було отримане в 1958 році за допомогою експерименту Мезельсона-Сталя, де було встановлено що ДНК реплікується напівконсервативно. Це була одна з трьох можливих моделей реплікації ДНК, разом з консервативною та розсіюючою моделями.[144] Подальші роботи Кріка і його лабораторії показали, що генетичний код засновується на трійках азотистих основ, що не перекриваються — кодонах. Це відкриття пізніше дозволило Гару Ґобінду Хорані, Роберту Голлі і Маршаллу Ніренбергу розшифрувати генетичний код, за що вони отримали Нобелівську премію з фізіології або медицини за 1968 рік.[145] Ці відкриття позначають початок молекулярної біології.
Див. також ред.
| Вікіцитати містять висловлювання на тему: Дезоксирибонуклеїнова кислота |
| Вікісховище має мультимедійні дані за темою: Дезоксирибонуклеїнова кислота |
- Генетична генеалогія
- ENCODE
- Епігенетика
- Мобільні елементи геному
- Мутація
- Нуклеопротеїни
- Генотерапія
- Генетична інженерія
- Центральна догма молекулярної біології
- 55555 ДНК — астероїд, названий на честь ДНК.
- День ДНК
Примітки ред.
- ↑ Raabe, Carsten A.; Brosius, Jürgen (April 2015). Does every transcript originate from a gene?. Annals of the New York Academy of Sciences. 1341: 136—148. doi:10.1111/nyas.12741. ISSN 1749-6632. PMID 25847549. Архів оригіналу за 7 листопада 2017. Процитовано 16 червня 2017.
{{cite journal}}: Cite має пустий невідомий параметр:|14=(довідка) - ↑ Cordaux, Richard; Batzer, Mark A. (October 2009). The impact of retrotransposons on human genome evolution. Nature reviews. Genetics. 10 (10): 691—703. doi:10.1038/nrg2640. ISSN 1471-0064. PMC 2884099. PMID 19763152. Архів оригіналу за 13 липня 2017. Процитовано 16 червня 2017.
{{cite journal}}: Cite має пустий невідомий параметр:|16=(довідка)Обслуговування CS1: Сторінки з PMC з іншим форматом (посилання) - ↑ RefSeq annotation of the human reference genome assembly. NCBI. Архів оригіналу за 28 січня 2019.
- ↑ Alberts, Bruce; Alexander Johnson, Julian Lewis, Martin Raff, Keith Roberts, and Peter Walters (2002). Molecular Biology of the Cell (вид. Fourth). New York and London: Garland Science. ISBN 0-8153-3218-1. Архів оригіналу за 18 жовтня 2007. Процитовано 3 листопада 2007.
- ↑ Butler, John M (2001). Forensic DNA Typing. Elsevier. с. 14-15. ISBN 978-0-12-147951-0.
- ↑ а б Berg J., Tymoczko J. and Stryer L (2002). Biochemistry. W. H. Freeman and Company. ISBN 0-7167-4955-6.
- ↑ а б А. В. Сиволоб (2008). Молекулярна біологія (PDF). К: Видавничо-поліграфічний центр "Київський університет". с. 70. Архів оригіналу (PDF) за 4 березня 2016. Процитовано 17 березня 2016.
- ↑ Abbreviations and Symbols for Nucleic Acids, Polynucleotides and their Constituents. IUPAC-IUB Commission on Biochemical Nomenclature (CBN). Архів оригіналу за 11 листопада 2007. Процитовано 3 січня 2006.
- ↑ Takahashi I, Marmur J. (1963). Replacement of thymidylic acid by deoxyuridylic acid in the deoxyribonucleic acid of а transducing phage for Bacillus subtilis. Nature. 197: 794—795. PMID 13980287.
- ↑ Agris P (2004). Decoding the genome: а modified view. Nucleic Acids Res. 32 (1): 223—238. PMID 14715921.[недоступне посилання з травня 2019]
- ↑ Bird A (2002). DNA methylation patterns and epigenetic memory. Genes Dev. 16 (1): 6—21. PMID 11782440.
- ↑ Klose R, Bird A (2006). Genomic DNA methylation: the mark and its mediators. Trends Biochem Sci. 31 (2): 89—97. PMID 16403636.
- ↑ Walsh C, Xu G. Cytosine methylation and DNA repair. Curr Top Microbiol Immunol. 301: 283—315. PMID 16570853.
- ↑ Ann Reisenauer, Lyn Sue Kahng, Susan McCollum, and Lucy Shapiro (1999). Bacterial DNA Methylation: a Cell Cycle Regulator?. Journal of Bacteriology. 181 (17): 5135—5139.
- ↑ Gommers-Ampt J, Van Leeuwen F, de Beer A, Vliegenthart J, Dizdaroglu M, Kowalak J, Crain P, Borst P (1993). beta-D-glucosyl-hydroxymethyluracil: а novel modified base present in the DNA of the parasitic protozoan T. brucei. Cell. 75 (6): 1129—36. PMID 8261512.
- ↑ а б Watson J, Crick F (1953). Molecular structure of nucleic acids; a structure for deoxyribose nucleic acid (PDF). Nature. 171 (4356): 737—8. PMID 13054692. Архів оригіналу (PDF) за 23 серпня 2014. Процитовано 3 листопада 2007.
- ↑ Mandelkern M, Elias J, Eden D, Crothers D (1981). The dimensions of DNA in solution. J Mol Biol. 152 (1): 153—61. PMID 7338906.
- ↑ А. В. Сиволоб, К. С. Афанасьєва (2012). Молекулярна організація хромосом (PDF). К: Видавничо-поліграфічний центр "Київський університет". Архів оригіналу (PDF) за 23 вересня 2015. Процитовано 17 березня 2016.
- ↑ Wing R, Drew H, Takano T, Broka C, Tanaka S, Itakura K, Dickerson R (1980). Crystal structure analysis of а complete turn of B-DNA. Nature. 287 (5784): 755—8. PMID 7432492.
- ↑ а б Pabo C, Sauer R (1984). PROTEIN-DNA recognition. Annu Rev Biochem. 53: 293—321. PMID 6236744.
- ↑ а б Zhou, Huiqing; Kimsey, Isaac J.; Nikolova, Evgenia N.; Sathyamoorthy, Bharathwaj; Grazioli, Gianmarc; McSally, James; Bai, Tianyu; Wunderlich, Christoph H.; Kreutz, Christoph (September 2016). m(1)A and m(1)G disrupt A-RNA structure through the intrinsic instability of Hoogsteen base pairs. Nature Structural & Molecular Biology. 23 (9): 803—810. doi:10.1038/nsmb.3270. ISSN 1545-9985. PMC 5016226. PMID 27478929. Архів оригіналу за 25 січня 2018. Процитовано 16 червня 2017.
{{cite journal}}: Cite має пустий невідомий параметр:|30=(довідка)Обслуговування CS1: Сторінки з PMC з іншим форматом (посилання) - ↑ Ponnuswamy P, Gromiha M (1994). On the conformational stability of oligonucleotide duplexes and tRNA molecules. J Theor Biol. 169 (4): 419—32. PMID 7526075.
- ↑ Clausen-Schaumann H, Rief M, Tolksdorf C, Gaub H (2000). Mechanical stability of single DNA molecules. Biophys J. 78 (4): 1997—2007. PMID 10733978.[недоступне посилання з травня 2019]
- ↑ Chalikian T, Völker J, Plum G, Breslauer K (1999). A more unified picture for the thermodynamics of nucleic acid duplex melting: а characterization by calorimetric and volumetric techniques. Proc Natl Acad Sci U S A. 96 (14): 7853—8. PMID 10393911.[недоступне посилання з травня 2019]
- ↑ а б в Hänsel-Hertsch, Robert; Di Antonio, Marco; Balasubramanian, Shankar (May 2017). DNA G-quadruplexes in the human genome: detection, functions and therapeutic potential. Nature Reviews. Molecular Cell Biology. 18 (5): 279—284. doi:10.1038/nrm.2017.3. ISSN 1471-0080. PMID 28225080. Архів оригіналу за 26 січня 2018. Процитовано 16 червня 2017.
{{cite journal}}: Cite має пустий невідомий параметр:|17=(довідка) - ↑ Kwok, Roberta (22 листопада 2012). Chemical biology: DNA's new alphabet. Nature (англ.). Т. 491, № 7425. с. 516—518. doi:10.1038/491516a.
- ↑ Lee, Kyung Hyun; Hamashima, Kiyofumi; Kimoto, Michiko; Hirao, Ichiro (16 жовтня 2017). Genetic alphabet expansion biotechnology by creating unnatural base pairs. Current Opinion in Biotechnology. Т. 51. с. 8—15. doi:10.1016/j.copbio.2017.09.006. ISSN 1879-0429. PMID 29049900. Архів оригіналу за 3 грудня 2017. Процитовано 23 листопада 2017.
{{cite news}}: Cite має пустий невідомий параметр:|18=(довідка) - ↑ а б Hayashi G, Hagihara M, Nakatani K (2005). Application of L-DNA as a molecular tag. Nucleic Acids Symp Ser (Oxf). 49: 261—262. PMID 17150733.
- ↑ Vargason JM, Eichman BF, Ho PS (2000). The extended and eccentric E-DNA structure induced by cytosine methylation or bromination. Nature Structural Biology. 7: 758—761. PMID 10966645.
- ↑ Wang G, Vasquez KM (2006). Non-B DNA structure-induced genetic instability. Mutat Res. 598 (1–2): 103—119. PMID 16516932.
- ↑ Allemand та ін. (1998). Stretched and overwound DNA forms a Pauling-like structure with exposed bases. PNAS. 24: 14152—14157. PMID 9826669.
{{cite journal}}: Явне використання «та ін.» у:|author=(довідка) - ↑ Ghosh A, Bansal M (2003). A glossary of DNA structures from A to Z. Acta Crystallogr D Biol Crystallogr. 59 (Pt 4): 620—6. PMID 12657780.
- ↑ Palecek E (1991). Local supercoil-stabilized DNA structures. Critical Reviews in Biochemistry and Molecular Biology. 26 (2): 151—226. PMID 1914495.
- ↑ Basu H, Feuerstein B, Zarling D, Shafer R, Marton L (1988). Recognition of Z-RNA and Z-DNA determinants by polyamines in solution: experimental and theoretical studies. J Biomol Struct Dyn. 6 (2): 299—309. PMID 2482766.
- ↑ Leslie AG, Arnott S, Chandrasekaran R, Ratliff RL (1980). Polymorphism of DNA double helices. J. Mol. Biol. 143 (1): 49—72. PMID 7441761.
- ↑ Wahl M, Sundaralingam M (1997). Crystal structures of A-DNA duplexes. Biopolymers. 44 (1): 45—63. PMID 9097733.
- ↑ Lu XJ, Shakked Z, Olson WK (2000). A-form conformational motifs in ligand-bound DNA structures. J. Mol. Biol. 300 (4): 819—40. PMID 10891271.
- ↑ Rothenburg S, Koch-Nolte F, Haag F. DNA methylation and Z-DNA formation as mediators of quantitative differences in the expression of alleles. Immunol Rev. 184: 286—98. PMID 12086319.
- ↑ Oh D, Kim Y, Rich A (2002). Z-DNA-binding proteins can act as potent effectors of gene expression in vivo. Proc. Natl. Acad. Sci. U.S.A. 99 (26): 16666—71. PMID 12486233.
- ↑ Thanbichler M, Wang S, Shapiro L (2005). The bacterial nucleoid: а highly organized and dynamic structure. J Cell Biochem. 96 (3): 506—21. PMID 15988757.
- ↑ а б в г д Bonev, Boyan; Cavalli, Giacomo (10 14, 2016). Organization and function of the 3D genome. Nature reviews. Genetics. 17 (11): 661—678. doi:10.1038/nrg.2016.112. ISSN 1471-0064. PMID 27739532. Архів оригіналу за 28 січня 2019. Процитовано 15 червня 2017.
- ↑ Bruce, Alberts,; Julian,, Lewis,; Martin,, Raff,; Keith,, Roberts,; Peter,, Walter, (2002). 4. DNA and Chromosomes. Molecular biology of the cell (вид. 4th ed). New York: Garland Science. ISBN 0815332181. OCLC 48122761. Архів оригіналу за 2 березня 2009. Процитовано 25 січня 2018.
- ↑ Lai, William K. M.; Pugh, B. Franklin (24 травня 2017). Understanding nucleosome dynamics and their links to gene expression and DNA replication. Nature Reviews. Molecular Cell Biology. doi:10.1038/nrm.2017.47. ISSN 1471-0080. PMID 28537572. Архів оригіналу за 28 вересня 2017. Процитовано 15 червня 2017.
{{cite journal}}: Cite має пустий невідомий параметр:|12=(довідка) - ↑ Fyodorov, Dmitry V.; Zhou, Bing-Rui; Skoultchi, Arthur I.; Bai, Yawen (March 2018). Emerging roles of linker histones in regulating chromatin structure and function. Nature Reviews. Molecular Cell Biology. Т. 19, № 3. с. 192—206. doi:10.1038/nrm.2017.94. ISSN 1471-0080. PMID 29018282. Архів оригіналу за 8 березня 2018. Процитовано 5 березня 2018.
{{cite news}}: Cite має пустий невідомий параметр:|19=(довідка) - ↑ Benham C, Mielke S (2005). DNA mechanics. Annu Rev Biomed Eng. 7: 21—53. PMID 16004565.
- ↑ а б Champoux J (2001). DNA topoisomerases: structure, function, and mechanism. Annu Rev Biochem. 70: 369—413. PMID 11395412.
- ↑ а б Wang J (2002). Cellular roles of DNA topoisomerases: a molecular perspective. Nat Rev Mol Cell Biol. 3 (6): 430—40. PMID 12042765.
- ↑ Greider C, Blackburn E (1985). Identification of а specific telomere terminal transferase activity in Tetrahymena extracts. Cell. 43 (2 Pt 1): 405—13. PMID 3907856.
- ↑ а б в Lazzerini-Denchi, Eros; Sfeir, Agnel (06 2016). Stop pulling my strings - what telomeres taught us about the DNA damage response. Nature Reviews. Molecular Cell Biology. 17 (6): 364—378. doi:10.1038/nrm.2016.43. ISSN 1471-0080. PMC 5385261. PMID 27165790. Архів оригіналу за 21 травня 2016. Процитовано 17 червня 2017.
{{cite journal}}: Cite має пусті невідомі параметри:|18=та|16=(довідка)Обслуговування CS1: Сторінки з PMC з іншим форматом (посилання) - ↑ а б в Nugent C, Lundblad V (1998). The telomerase reverse transcriptase: components and regulation. Genes Dev. 12 (8): 1073—85. PMID 9553037. Архів оригіналу за 27 вересня 2007. Процитовано 4 листопада 2007.
- ↑ Wright W, Tesmer V, Huffman K, Levene S, Shay J (1997). Normal human chromosomes have long G-rich telomeric overhangs at one end. Genes Dev. 11 (21): 2801—9. PMID 9353250. Архів оригіналу за 27 вересня 2007. Процитовано 4 листопада 2007.
- ↑ а б Burge S, Parkinson G, Hazel P, Todd A, Neidle S (2006). Quadruplex DNA: sequence, topology and structure. Nucleic Acids Res. 34 (19): 5402—15. PMID 17012276.[недоступне посилання з травня 2019]
- ↑ Зроблено за даними PDB UD0017
- ↑ Sandman K, Pereira S, Reeve J (1998). Diversity of prokaryotic chromosomal proteins and the origin of the nucleosome. Cell Mol Life Sci. 54 (12): 1350—64. PMID 9893710.
- ↑ Dame RT (2005). The role of nucleoid-associated proteins in the organization and compaction of bacterial chromatin. Mol. Microbiol. 56 (4): 858—70. PMID 15853876.
- ↑ L'ubomíra Čuboňová, Kathleen Sandman, Steven J. Hallam, Edward F. DeLong, and John N. Reeve (2005). Histones%20in%20Crenarchaea. Journal of Bacteriology. 187 (15): 5482—5485. PMID 16030242.
- ↑ J.N. Reeve, K.A. Bailey, W-t. Li, F. Marc, K. Sandman and D.J. Soares (2004). Archaeal histones: structures, stability and DNA binding (PDF). Biochemical Society Transactions. 32 (2): 227—230. PMID 15046577.
- ↑ Mirny, Leonid A. (January 2011). The fractal globule as a model of chromatin architecture in the cell. Chromosome Research: An International Journal on the Molecular, Supramolecular and Evolutionary Aspects of Chromosome Biology. Т. 19, № 1. с. 37—51. doi:10.1007/s10577-010-9177-0. ISSN 1573-6849. PMC 3040307. PMID 21274616. Архів оригіналу за 1 лютого 2018. Процитовано 25 січня 2018.
{{cite news}}: Cite має пустий невідомий параметр:|15=(довідка)Обслуговування CS1: Сторінки з PMC з іншим форматом (посилання) - ↑ Luger K, Mäder A, Richmond R, Sargent D, Richmond T (1997). Crystal structure of the nucleosome core particle at 2.8 A resolution. Nature. 389 (6648): 251—60. PMID 9305837.
- ↑ Jenuwein T, Allis C (2001). Translating the histone code. Science. 293 (5532): 1074—80. PMID 11498575.
- ↑ Ito T. Nucleosome assembly and remodelling. Curr Top Microbiol Immunol. 274: 1—22. PMID 12596902.
- ↑ Soutourina, Julie (6 грудня 2017). Transcription regulation by the Mediator complex. Nature Reviews. Molecular Cell Biology. doi:10.1038/nrm.2017.115. ISSN 1471-0080. PMID 29209056. Архів оригіналу за 5 червня 2018. Процитовано 25 січня 2018.
- ↑ Thomas J (2001). HMG1 and 2: architectural DNA-binding proteins. Biochem Soc Trans. 29 (Pt 4): 395—401. PMID 11497996.
- ↑ Grosschedl R, Giese K, Pagel J (1994). HMG domain proteins: architectural elements in the assembly of nucleoprotein structures. Trends Genet. 10 (3): 94—100. PMID 8178371.
- ↑ Blanco, Mélina; Cocquet, Julie (2019). Genetic Factors Affecting Sperm Chromatin Structure. Advances in Experimental Medicine and Biology. 1166: 1—28. doi:10.1007/978-3-030-21664-1_1. ISSN 0065-2598. PMID 31301043.
- ↑ Iftode C, Daniely Y, Borowiec J (1999). Replication protein A (RPA): the eukaryotic SSB. Crit Rev Biochem Mol Biol. 34 (3): 141—80. PMID 10473346.
- ↑ Myers L, Kornberg R. Mediator of transcriptional regulation. Annu Rev Biochem. 69: 729—49. PMID 10966474.
- ↑ Spiegelman B, Heinrich R (2004). Biological control through regulated transcriptional coactivators. Cell. 119 (2): 157—67. PMID 15479634.
- ↑ Li Z, Van Calcar S, Qu C, Cavenee W, Zhang M, Ren B (2003). A global transcriptional regulatory role for c-Myc in Burkitts lymphoma cells. Proc Natl Acad Sci U S A. 100 (14): 8164—9. PMID 12808131.[недоступне посилання з травня 2019]
- ↑ Schoeffler A, Berger J (2005). Recent advances in understanding structure-function relationships in the type II topoisomerase mechanism. Biochem Soc Trans. 33 (Pt 6): 1465—70. PMID 16246147.
- ↑ Tuteja N, Tuteja R (2004). Unraveling DNA helicases. Motif, structure, mechanism and function. Eur J Biochem. 271 (10): 1849—63. PMID 15128295.[недоступне посилання з травня 2019]
- ↑ Bickle T, Krüger D (1993). Biology of DNA restriction. Microbiol Rev. 57 (2): 434—50. PMID 8336674.[недоступне посилання з травня 2019]
- ↑ Doherty A, Suh S (2000). Structural and mechanistic conservation in DNA ligases. Nucleic Acids Res. 28 (21): 4051—8. PMID 11058099. Архів оригіналу за 24 вересня 2019. Процитовано 30 листопада 2007.
- ↑ Joyce C, Steitz T (1995). Polymerase structures and function: variations on а theme?. J Bacteriol. 177 (22): 6321—9. PMID 7592405.[недоступне посилання з травня 2019]
- ↑ Нуклеїнові ази. 13 Липня 2012. Архів оригіналу за 10 квітня 2017.
- ↑ Hubscher U, Maga G, Spadari S. Eukaryotic DNA polymerases. Annu Rev Biochem. 71: 133—63. PMID 12045093.
- ↑ Johnson A, O'Donnell M. Cellular DNA replicases: components and dynamics at the replication fork. Annu Rev Biochem. 74: 283—315. PMID 15952889.
- ↑ Tarrago-Litvak L, Andréola M, Nevinsky G, Sarih-Cottin L, Litvak S (1994). The reverse transcriptase of HIV-1: from enzymology to therapeutic intervention. FASEB J. 8 (8): 497—503. PMID 7514143. Архів оригіналу за 16 травня 2007. Процитовано 17 листопада 2007.
- ↑ Martinez E (2002). Multi-protein complexes in eukaryotic gene transcription. Plant Mol Biol. 50 (6): 925—47. PMID 12516863.
- ↑ Реплікацію ДНК вперше зняли на відео. Архів оригіналу за 6 березня 2018. Процитовано 28 червня 2017.
- ↑ Albà M (2001). Replicative DNA polymerases. Genome Biol. 2 (1): REVIEWS3002. PMID 11178285.[недоступне посилання з травня 2019]
- ↑ Williams, Jessica S.; Lujan, Scott A.; Kunkel, Thomas A. (06 2016). Processing ribonucleotides incorporated during eukaryotic DNA replication. Nature Reviews. Molecular Cell Biology. 17 (6): 350—363. doi:10.1038/nrm.2016.37. ISSN 1471-0080. PMC 5445644. PMID 27093943. Архів оригіналу за 23 липня 2018. Процитовано 18 червня 2017.
{{cite journal}}: Cite має пустий невідомий параметр:|18=(довідка)Обслуговування CS1: Сторінки з PMC з іншим форматом (посилання) - ↑ Cremer T, Cremer C (2001). Chromosome territories, nuclear architecture and gene regulation in mammalian cells. Nat Rev Genet. 2 (4): 292—301. PMID 11283701.
- ↑ Pál C, Papp B, Lercher M (2006). An integrated view of protein evolution. Nat Rev Genet. 7 (5): 337—48. PMID 16619049.
- ↑ ODriscoll M, Jeggo P (2006). The role of double-strand break repair - insights from human genetics. Nat Rev Genet. 7 (1): 45—54. PMID 16369571.
- ↑ Dickman M, Ingleston S, Sedelnikova S, Rafferty J, Lloyd R, Grasby J, Hornby D (2002). The RUVABC resolvasome. Eur J Biochem. 269 (22): 5492—501. PMID 12423347.
- ↑ Зроблено за даними PDB 1JDG
- ↑ Douki T, Reynaud-Angelin A, Cadet J, Sage E (2003). Bipyrimidine photoproducts rather than oxidative lesions are the main type of DNA damage involved in the genotoxic effect of solar UVA radiation. Biochemistry. 42 (30): 9221—6. PMID 12885257.
- ↑ Cadet J, Delatour T, Douki T, Gasparutto D, Pouget J, Ravanat J, Sauvaigo S (1999). Hydroxyl radicals and DNA base damage. Mutat Res. 424 (1 – 2): 9—21. PMID 10064846.
- ↑ Shigenaga M, Gimeno C, Ames B (1989). Urinary 8-hydroxy-2′-deoxyguanosine as a biological marker of in vivo oxidative DNA damage. Proc Natl Acad Sci U S A. 86 (24): 9697—701. PMID 2602371. Архів оригіналу за 31 жовтня 2007. Процитовано 4 листопада 2007.
- ↑ Cathcart R, Schwiers E, Saul R, Ames B (1984). Thymine glycol and thymidine glycol in human and rat urine: a possible assay for oxidative DNA damage (PDF). Proc Natl Acad Sci U S A. 81 (18): 5633—7. PMID 6592579. Архів оригіналу (PDF) за 31 жовтня 2007. Процитовано 4 листопада 2007.
- ↑ Ferguson L, Denny W (1991). The genetic toxicology of acridines. Mutat Res. 258 (2): 123—60. PMID 1881402.
- ↑ Jeffrey A (1985). DNA modification by chemical carcinogens. Pharmacol Ther. 28 (2): 237—72. PMID 3936066.
- ↑ Stephens T, Bunde C, Fillmore B (2000). Mechanism of action in thalidomide teratogenesis. Biochem Pharmacol. 59 (12): 1489—99. PMID 10799645.
- ↑ Toxicity Effects. tools.niehs.nih.gov (англ.). National Toxicology Program. Архів оригіналу за 6 березня 2018. Процитовано 5 березня 2018.
{{cite web}}: Cite має пустий невідомий параметр:|6=(довідка) - ↑ Braña M, Cacho M, Gradillas A, de Pascual-Teresa B, Ramos A (2001). Intercalators as anticancer drugs. Curr Pharm Des. 7 (17): 1745—80. PMID 11562309.
- ↑ Stingele, Julian; Jentsch, Stefan. DNA–protein crosslink repair. Nature Reviews Molecular Cell Biology. 16 (8): 455—460. doi:10.1038/nrm4015.
- ↑ Wolfsberg T, McEntyre J, Schuler G (2001). Guide to the draft human genome. Nature. 409 (6822): 824—6. PMID 11236998.
- ↑ Gregory T (2005). The C-value enigma in plants and animals: а review of parallels and an appeal for partnership. Ann Bot (Lond). 95 (1): 133—46. PMID 15596463. Архів оригіналу за 16 травня 2007. Процитовано 9 листопада 2007.
- ↑ Pidoux A, Allshire R (2005). The role of heterochromatin in centromere function (PDF). Philos Trans R Soc Lond B Biol Sci. 360 (1455): 569—79. PMID 15905142.[недоступне посилання з травня 2019]
- ↑ Harrison P, Hegyi H, Balasubramanian S, Luscombe N, Bertone P, Echols N, Johnson T, Gerstein M (2002). Molecular fossils in the human genome: identification and analysis of the pseudogenes in chromosomes 21 and 22. Genome Res. 12 (2): 272—80. PMID 11827946. Архів оригіналу за 28 жовтня 2007. Процитовано 9 листопада 2007.
- ↑ Harrison P, Gerstein M (2002). Studying genomes through the aeons: protein families, pseudogenes and proteome evolution. J Mol Biol. 318 (5): 1155—74. PMID 12083509.
- ↑ Soller M (2006). Molecular fossils in the human genome: identification and analysis of the pseudogenes in chromosomes 21 and 22. Cell Mol Life Sci. 63 (7-9): 796—819. PMID 16465448.[недоступне посилання з січня 2019]
- ↑ Michalak P. (2006). RNA world - the dark matter of evolutionary genomics. 19 (6): 1768—74. PMID 17040373. Архів оригіналу за 28 січня 2019. Процитовано 9 листопада 2007.
- ↑ ENCODE Project Consortium (6 вересня 2012). An integrated encyclopedia of DNA elements in the human genome. Nature. 489 (7414): 57—74. doi:10.1038/nature11247. ISSN 1476-4687. PMC 3439153. PMID 22955616. Архів оригіналу за 8 липня 2017. Процитовано 18 червня 2017.
{{cite journal}}: Cite має пустий невідомий параметр:|13=(довідка)Обслуговування CS1: Сторінки з PMC з іншим форматом (посилання) - ↑ Engreitz, Jesse M.; Ollikainen, Noah; Guttman, Mitchell (12 2016). Long non-coding RNAs: spatial amplifiers that control nuclear structure and gene expression. Nature Reviews. Molecular Cell Biology. 17 (12): 756—770. doi:10.1038/nrm.2016.126. ISSN 1471-0080. PMID 27780979. Архів оригіналу за 25 січня 2018. Процитовано 18 червня 2017.
{{cite journal}}: Cite має пустий невідомий параметр:|17=(довідка) - ↑ Joyce G (2002). The antiquity of RNA-based evolution. Nature. 418 (6894): 214—21. PMID 12110897.
- ↑ Orgel L. Prebiotic chemistry and the origin of the RNA world (PDF). Crit Rev Biochem Mol Biol. 39 (2): 99—123. PMID 15217990. Архів оригіналу (PDF) за 27 листопада 2007. Процитовано 18 листопада 2007.
- ↑ Davenport R (2001). Ribozymes. Making copies in the RNA world. Science. 292 (5520): 1278. PMID 11360970.
- ↑ Szathmáry E (1992). What is the optimum size for the genetic alphabet? (PDF). Proc Natl Acad Sci U S A. 89 (7): 2614—8. PMID 1372984. Архів оригіналу (PDF) за 27 листопада 2007. Процитовано 18 листопада 2007.
- ↑ Vreeland R, Rosenzweig W, Powers D (2000). Isolation of а 250 million-year-old halotolerant bacterium from а primary salt crystal. Nature. 407 (6806): 897—900. PMID 11057666.
- ↑ Hebsgaard M, Phillips M, Willerslev E (2005). Geologically ancient DNA: fact or artefact?. Trends Microbiol. 13 (5): 212—20. PMID 15866038.
- ↑ Nickle D, Learn G, Rain M, Mullins J, Mittler J (2002). Curiously modern DNA for a "250 million-year-old" bacterium. J Mol Evol. 54 (1): 134—7. PMID 11734907.
- ↑ Kaplan, Matt. DNA has a 521-year half-life. Nature (англ.). doi:10.1038/nature.2012.11555. Процитовано 18 червня 2017.
- ↑ Nature focus mouse ENCODE. Nature.
- ↑ Goff SP, Berg P (1976). Construction of hybrid viruses containing SV40 and lambda phage DNA segments and their propagation in cultured monkey cells. Cell. 9 (4 PT 2): 695—705. PMID 189942.
- ↑ Houdebine L. Transgenic animal models in biomedical research. Methods Mol Biol. 360: 163—202. PMID 17172731.
- ↑ Daniell H, Dhingra A (2002). Multigene engineering: dawn of an exciting new era in biotechnology. Curr Opin Biotechnol. 13 (2): 136—41. PMID 11950565.
- ↑ Job D (2002). Plant biotechnology in agriculture. Biochimie. 84 (11): 1105—10. PMID 12595138.
- ↑ Collins A, Morton N (1994). Likelihood ratios for DNA identification (PDF). Proc Natl Acad Sci U S A. 91 (13): 6007—11. PMID 8016106. Архів оригіналу (PDF) за 27 листопада 2007. Процитовано 18 листопада 2007.
- ↑ Weir B, Triggs C, Starling L, Stowell L, Walsh K, Buckleton J (1997). Interpreting DNA mixtures. J Forensic Sci. 42 (2): 213—22. PMID 9068179.
- ↑ Jeffreys A, Wilson V, Thein S. Individual-specific fingerprints of human DNA. Nature. 316 (6023): 76—9. PMID 2989708.
- ↑ Colin Pitchfork — first murder conviction on DNA evidence also clears the prime suspect. Архів оригіналу за 14 грудня 2006. Процитовано 18 листопада 2007.
- ↑ DNA Identification in Mass Fatality Incidents. National Institute of Justice. September 2006. Архів оригіналу за 25 лютого 2012. Процитовано 18 листопада 2007.
- ↑ Baldi, Pierre. Brunak, Soren (2001). Bioinformatics: The Machine Learning Approach. Cambridge, MA: MIT Press. ISBN 978-0-262-02506-5.
- ↑ Gusfield, Dan. (15 січня 1997). Algorithms on Strings, Trees, and Sequences: Computer Science and Computational Biology. Cambridge University Press. ISBN 978-0-521-58519-4.
- ↑ Sjölander K (2004). Phylogenomic inference of protein molecular function: advances and challenges. Bioinformatics. 20 (2): 170—9. PMID 14734307. Архів оригіналу за 11 жовтня 2008. Процитовано 18 листопада 2007.
- ↑ Mount DM (2004). Bioinformatics: Sequence and Genome Analysis (вид. 2). Cold Spring Harbor, NY: Cold Spring Harbor Laboratory Press. ISBN 0-87969-712-1.
- ↑ Adleman L (1994). Molecular computation of solutions to combinatorial problems. Science. 266 (5187): 1021—4. PMID 7973651.
- ↑ Parker J (2003). Computing with DNA. EMBO Rep. 4 (1): 7—10. PMID 12524509.
- ↑ Ashish Gehani, Thomas LaBean and John Reif. DNA-Based Cryptography [Архівовано 11 жовтня 2007 у Wayback Machine.]. Proceedings of the 5th DIMACS Workshop on DNA Based Computers, Cambridge, MA, USA, 14 — 15 June 1999
- ↑ Wray G (2002). Dating branches on the tree of life using DNA. Genome Biol. 3 (1): REVIEWS0001. PMID 11806830. Архів оригіналу за 24 вересня 2019. Процитовано 18 листопада 2007.
- ↑ Watson, Traci (1 червня 2017). Mummy DNA unravels ancient Egyptians’ ancestry. Nature (англ.). Т. 546, № 7656. с. 17—17. doi:10.1038/546017a.
{{cite news}}: Cite має пустий невідомий параметр:|1=(довідка) - ↑ Callaway, Ewen. Evidence mounts for interbreeding bonanza in ancient human species. Nature (англ.). doi:10.1038/nature.2016.19394. Процитовано 18 червня 2017.
- ↑ Charles Jencks' DNA family. ?What's Life? [Архівовано 7 лютого 2018 у Wayback Machine.](англ.)
- ↑ Helix Bridge / Cox Architecture with Architects 61. Project at ArchDaily [Архівовано 1 грудня 2017 у Wayback Machine.](англ.)
- ↑ 2003 Discovery of DNA £2. The Royl Mint [Архівовано 29 січня 2018 у Wayback Machine.](англ.)
- ↑ What does DNA sound like? Mark Temple. Using music to unlock the secrets of genetic code. The Conversation, June 20, 2017 [Архівовано 29 січня 2018 у Wayback Machine.](англ.)
- ↑ Temple, Mark D. (2017). An auditory display tool for DNA sequence analysis. BMC Bioinformatics. 18 (1). doi:10.1186/s12859-017-1632-x. ISSN 1471-2105.
{{cite journal}}: Обслуговування CS1: Сторінки із непозначеним DOI з безкоштовним доступом (посилання)(англ.) - ↑ Dahm R (2005). Friedrich Miescher and the discovery of DNA. Dev Biol. 278 (2): 274—88. PMID 15680349.
- ↑ Hershey A, Chase M (1952). Independent functions of viral protein and nucleic acid in growth of bacteriophage (PDF). J Gen Physiol. 36 (1): 39—56. PMID 12981234. Архів оригіналу (PDF) за 25 вересня 2007. Процитовано 2 вересня 2007.
- ↑ The Nobel Prize in Physiology or Medicine 1962. Nobelprize.org. Архів оригіналу за 4 січня 2007. Процитовано 22 грудня 2006.
- ↑ Crick, F.H.C. (1955). On degenerate templates and the adaptor hypothesis (Lecture) (PDF). genome.wellcome.ac.uk. Архів оригіналу (PDF) за 20 червня 2013. Процитовано 22 грудня 2006.
- ↑ Meselson M, Stahl F (1958). The replication of DNA in Escherichia coli. Proc Natl Acad Sci U S A. 44 (7): 671—82. PMID 16590258.
- ↑ The Nobel Prize in Physiology or Medicine 1968. Nobelprize.org. Архів оригіналу за 3 січня 2007. Процитовано 22 грудня 2006.
Рекомендована література ред.
- А. В. Сиволоб, К. С. Афанасьєва (2012). Молекулярна організація хромосом (PDF). К: Видавничо-поліграфічний центр "Київський університет". с. ?. Архів оригіналу (PDF) за 23 вересня 2015. Процитовано 17 березня 2016. .- 126 с.
- Фізика ДНК : навчальний посібник / А. В. Сиволоб. – К. : Видавничополіграфічний центр "Київський університет", 2011. – 335 с. Ел.джерело [Архівовано 23 листопада 2018 у Wayback Machine.] ISBN 978-966-439-468-3
- А. В. Сиволоб (2008). Молекулярна біологія (PDF). К: Видавничо-поліграфічний центр "Київський університет". с. ?. Архів оригіналу (PDF) за 4 березня 2016. Процитовано 17 березня 2016.
- Bruce, Alberts. Molecular biology of the cell. с. ?. ISBN 9780815344322. OCLC 887605755. Архів оригіналу за 20 квітня 2021. Процитовано 17 червня 2017.
Література ред.
- Зламати ДНК. Редагування генома та контроль над еволюцією. Дженніфер Дудна, Семюель Стернберг/Перекладач: Ганна Литвиненко.- Наш Формат, 2019.- 296 с. ISBN 978-617-773-053-7
- Генплан. Як ДНК робить нас тими, ким ми є (Blueprint. How DNA Makes Us Who We Are). Роберт Пломін.- 2019.- 320 с. ISBN 978-966-948-194-8
- Річард Докінз. Егоїстичний ген. Переклад з англійської: Я. А. Лебеденко. Харків: КСД, 2017. 540 стор. ISBN 978-617-12-2523-7
- (рос.)История биологии с начала XX века до наших дней. М.: Наука, 1975. 660 с.
- (рос.)Льюин Б. Гены. М.: Мир, 1987. 1064 с.
- (рос.)Пташне М. Переключение генов. Регуляция генной активности и фаг лямбда. [Архівовано 30 жовтня 2007 у Wayback Machine.] М.: Мир, 1989. 160 с., ISBN 5-03-000854-3
- (рос.)Уотсон Дж. Д. Двойная спираль: воспоминания об открытии структуры ДНК. М.: Мир, 1969. 152 с. ISBN 5-93972-054
Посилання ред.
- Міжнародна база даних [Архівовано 3 липня 2009 у Wayback Machine.] — послідовності ДНК різних організмів (англ.).
- Реплікація ДНК (анімація) (англ.)
- Сайт Сенгерівського інституту [Архівовано 21 листопада 2007 у Wayback Machine.], одного із світових лідерів в галузі визначення послідовностей ДНК і їхнього аналізу (англ.)
Відео ред.
- Що таке ДНК, гени та спадкові хвороби 2020, youtube, 9хв 45сек
| Ця стаття належить до вибраних статей Української Вікіпедії. |